"Now we have RL scaling and there's no publicly known scaling law for it. It's not even clear what the story is. Is this supposed to be teaching the model skills? Is it supposed to be teaching meta-learning? What is the scaling hypothesis at this point?"
— Dwarkesh Patel, interview with Dario Amodei
Introduction
Despite RLVR's growing role in the frontier model training pipeline, it remains unclear how the resulting performance gains are achieved. Yue et al. (2025) showed that RL does not teach models reasoning strategies absent from the base distribution. They show this by demonstrating that pass@k at sufficiently high k does not increase under RL training. However, this raises a natural follow-up question: in what ways does RL sharpen the distribution?
The answer likely involves some combination of task-specific cognitive strategies (e.g. which formula to apply), meta-cognitive strategies (e.g. when to verify or backtrack), formatting and instruction-following, shortcutting to simpler heuristics, or novel compositions of existing cognitive strategies (Yuan et al., 2026). Understanding which of these mechanisms dominate in a given setting has practical implications: if we can identify which configurations yield desirable cognitive behaviors, we can design better RL training pipelines. Conversely, if certain models lack the cognitive behaviors necessary for RL to be effective (Gandhi et al., 2025), targeted interventions, such as priming those behaviors through prompting or fine-tuning before RL training, might prove useful.
Consider another learning-from-experience paradigm: reflective prompt optimization (RPO). RPO methods such as GEPA (Agrawal et al., 2026) optimize prompts in token-space after analyzing rollouts, enabling direct interpretation of what was learned by simply reading the optimized prompt. Policy-gradient RLVR, on the other hand, learns in weight-space, making interpretation harder. To make progress, we propose looking at the outputs: defining a set of cognitive and meta-cognitive behaviors and measuring how their distributions in model reasoning traces shift under RLVR.
We operationalize this approach using Schoenfeld's (1985) episode theory from mathematics education. We adopt the sentence-level operationalization developed by Li et al. (2025), who adapted Schoenfeld's original episode categories into seven labels (Read, Analyze, Plan, Implement, Explore, Verify, and Monitor) suitable for classifying individual sentences in LLM reasoning traces. We build an LLM-based sentence-level judge, calibrated against Li et al.'s hand-labeled ground-truth corpus of 2,777 sentences across 38 traces, achieving 72.5% accuracy and 0.71 macro F1 on this 7-class classification problem (compared to 68.1% reported by Li et al.).
We apply this measurement methodology across five experimental configurations, systematically varying the task, model, and prompt while holding the analytical framework fixed.
Our main findings are:
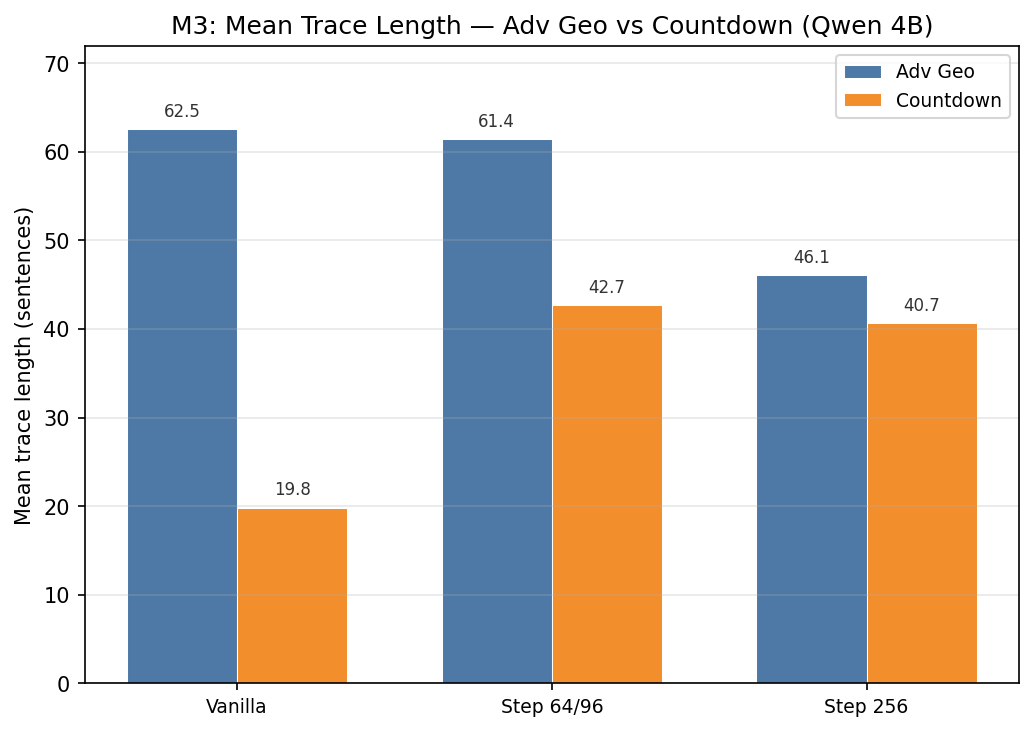
- Behavioral shifts are task-dependent. On Advanced Geometry, RL mostly shortens traces and leaves the episode mix broadly similar; on Countdown, it redistributes mass away from Implement and toward planning and verification. RL shortens Advanced Geometry traces but lengthens Countdown traces.
- RL can teach both aligned and misaligned cognitive strategies, independent of increasing reward. On Advanced Geometry, Llama completely switches from Heron's formula to the coordinate area formula. On Countdown, the RL-trained Llama model nearly eliminates multiplication and division in favor of addition and subtraction.
- A carefully chosen single in-context example dramatically alters RL's trajectory. Adding one worked example to Llama's prompt on Countdown roughly doubles final reward and transforms the behavioral fingerprint.
- Model families differ in their baseline behavioral fingerprints and in how RL modifies them, consistent with prior observations by Gandhi et al. (2025).
Related Work
What does RLVR teach?
Yue et al. (2025) provide evidence that RLVR does not expand the set of reasoning strategies available to a model, but rather sharpens the sampling distribution toward strategies that were already present at low probability in the base model. Our work is complementary: given this characterization, we ask how the sharpening manifests in patterns in reasoning traces.
Cognitive behaviors in LLM reasoning
Gandhi et al. (2025) identify specific metacognitive behaviors (verification, backtracking, subgoal setting, and backward chaining) that emerge under RLVR in Qwen but not in Llama, and show that fine-tuning Llama on traces exhibiting these behaviors recovers the RL performance gap. Our work uses a different behavioral taxonomy (Schoenfeld episodes) and focuses on measuring distributional shifts across tasks and prompts.
Schoenfeld's episode theory
Schoenfeld's (1985) framework was originally developed to analyze how mathematics students work through problems. Li et al. (2025) adapted this framework for LLM reasoning traces, defining sentence-level labels and providing a hand-annotated corpus. We build on their operationalization and use their ground-truth data to calibrate our judge.
Inference-time scaling
The observation that RL training can enable inference-time scaling has been documented in several recent works (OpenAI, 2024; Snell et al., 2025). Our trace-length analysis provides a behavioral view of this phenomenon, showing that the relationship between RL and trace length is task-dependent, model-dependent, and training-algorithm-dependent and that increased length does not uniformly correspond to productive reasoning. In particular, we find that RL-trained models scale inference disproportionately on incorrect problems (presumably harder ones).
Method
Overview
Our methodology consists of three components: (1) training models with GRPO across multiple configurations, (2) generating reasoning traces from vanilla and RL-trained checkpoints on held-out test problems, and (3) measuring how the distribution of Schoenfeld episode labels changes across checkpoints.
Schoenfeld Episode Labeling
We classify each sentence in a reasoning trace into one of seven categories adapted from Schoenfeld's (1985) episode theory by Li et al. (2025):
- Read: Restating or extracting information directly from the problem.
- Analyze: Recalling theories, introducing symbols, and making logical deductions without concrete calculations.
- Plan: Announcing the next step or outlining a solution strategy before execution begins.
- Implement: Performing calculations, substituting values, and producing intermediate or final results.
- Explore: Generating tentative ideas or trying alternatives without committing, often marked by hedging language.
- Verify: Checking correctness or validating results by plugging back in, cross-checking, or estimating bounds.
- Monitor: Brief meta-cognitive interjections: hesitations or reflections signaling internal processing flow (e.g., "Hmm, wait. Let me think about this.").
| Sentence | Label |
|---|---|
| "The problem gives me the volume, which is 432 cubic centimeters, and the area of the base, which is 24 square centimeters." | Read |
| "Since they give me the volume and the base area, I can solve for the height." | Analyze |
| "Let me start by looking at the original expression and then compare it to each of the options A through D." | Plan |
| "Plugging in the numbers they gave: \(h = 432 \text{ cm}^3 / 24 \text{ cm}^2\)." | Implement |
| "Hmm, intersecting the y-axis at exactly one point means that the circle is tangent to the y-axis, right?" | Explore |
| "Okay, so both methods give me the same answer." | Verify |
| "Wait, let's think." | Monitor |
LLM-as-a-judge. We use an LLM-based sentence-level judge (GPT-5-mini) that takes as input the full reasoning trace, the target sentence to label, and the taxonomy guide, and outputs a single label for the target sentence. We chose sentence-level rather than trace-level judging because our benchmarking showed it produces lower Jensen-Shannon divergence from ground-truth label distributions (mean JS = 0.024 vs. 0.034 for the trace-level judge), while achieving a true sentence-level accuracy of 72.5% and macro F1 of 0.71 on the 38-trace, 2,777-sentence ground-truth corpus from Li et al. For comparison, the best accuracy reported by Li et al. was 68.1%. Naive baselines of uniform distribution and global-frequency distribution achieve JS divergences of 0.086 and 0.053, respectively, confirming that our judge captures meaningful distributional information well above chance.
Training Setup
We train using GRPO (Shao et al., 2024) via the Tinker training API. Common hyperparameters across all runs: learning rate \(10^{-5}\), importance sampling loss, zero KL penalty and discount, batch size \(8 \times 64\) (groups × group size), LoRA rank 32. All models are trained for up to 256 GRPO steps. For each run, we evaluate the base model, a representative intermediate checkpoint, and the final step-256 checkpoint. The intermediate checkpoint is the saved checkpoint whose test reward is closest to halfway between the base model's test reward and the step-256 test reward.
Tasks
Both tasks are drawn from the ReasoningGym benchmark (Stojanovski et al., 2025):
Countdown. Given a list of N numbers and a target value, find an arithmetic expression using all numbers exactly once that evaluates to the target. This is a combinatorial search/planning problem, so additional inference-time compute can help by exploring more candidate expressions.
Question. Using all the numbers 74, 48, 56, 66, create an expression that equals 132. You can only use each number once.
Solution.
66 - 56 + 74 + 48
For the Countdown experiments, we used an easier 3–4-term configuration for Llama and the standard 4–6-term configuration for Qwen, because the vanilla Llama model struggled at step 0 on the 4–6-term setting.
Advanced Geometry. Given the coordinates of a triangle's vertices, compute a derived quantity (incircle radius, orthocenter, or angle measure). This requires selecting and correctly applying the right formula, making it a more procedural task where the main challenge is formula selection and error-free computation.
Question. Find the incircle radius of triangle ABC whose vertices are \(A=(6,7)\), \(B=(-7,-5)\), and \(C=(2,-3)\).
Solution. 2.176
Experimental Configurations
We study Llama 3.1 8B Instruct and Qwen3 4B Instruct; for brevity, we refer to them as Llama and Qwen below.
| Run | Task | Model | Prompt | Checkpoints |
|---|---|---|---|---|
| 1 | Countdown | Llama 3.1 8B Instruct | Zero-shot | Base, 32, 256 |
| 2 | Countdown | Qwen3 4B Instruct | Zero-shot | Base, 96, 256 |
| 3 | Countdown | Llama 3.1 8B Instruct | One-shot | Base, 64, 256 |
| 4 | Advanced Geometry | Llama 3.1 8B Instruct | Zero-shot | Base, 96, 256 |
| 5 | Advanced Geometry | Qwen3 4B Instruct | Zero-shot | Base, 64, 256 |
For each configuration, we compare the vanilla (base) model against RL-trained checkpoints on the same 200 held-out test problems. We report accuracy, mean trace length (in sentences), Schoenfeld episode distributions, and qualitative analysis of strategy selection.
Results
Accuracy Improvements
| Run | Task | Model | Prompt | Vanilla (%) | Final (%) |
|---|---|---|---|---|---|
| 1 | Countdown | Llama | Zero-shot | 8.0 | 42.0 |
| 2 | Countdown | Qwen | Zero-shot | 37.5 | 67.0 |
| 3 | Countdown | Llama | One-shot | 7.0 | 83.0 |
| 4 | Advanced Geometry | Llama | Zero-shot | 1.5 | 29.5 |
| 5 | Advanced Geometry | Qwen | Zero-shot | 41.0 | 59.5 |
RLVR consistently improves accuracy, with the magnitude depending on the configuration. The most dramatic improvement comes from Llama on one-shot Countdown, a point we return to below.
Behavioral Shifts Are Task-Dependent
Episode distributions shift differently across tasks. The figure below shows the mean-trace Schoenfeld episode distributions for Qwen on Advanced Geometry and Countdown, with Llama on Advanced Geometry added for comparison. We omit zero-shot Llama Countdown from this visualization because its traces average only 1.2–1.7 sentences, making sentence-level episode fingerprints too sparse to be very informative.
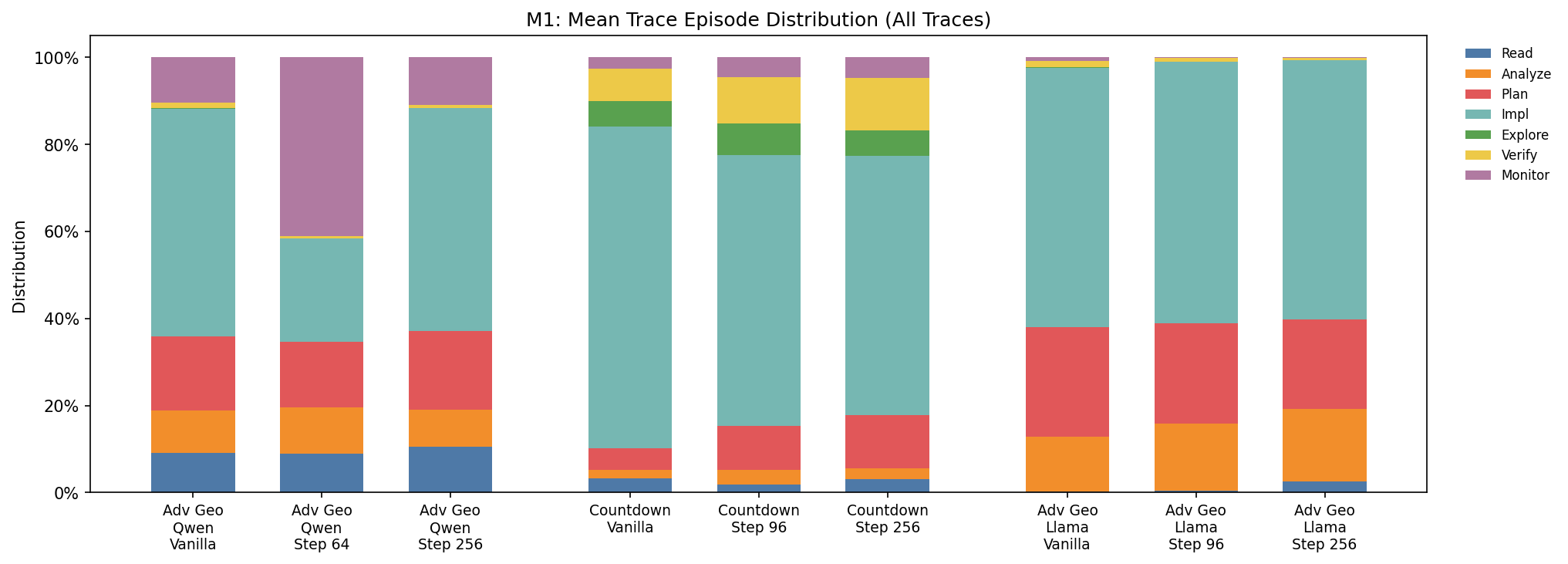
On Advanced Geometry (Qwen), the changes are modest. This suggests that on Advanced Geometry, RL mostly preserves the broad cognitive structure of the trace. On Countdown (Qwen), the shifts are much larger:
- Implement: decreases sharply from 73.9% to 59.6%.
- Plan: increases from 4.9% to 12.2%.
- Verify: increases from 7.3% to 12.0%.
- Monitor: increases while Explore is essentially unchanged.
Countdown is a combinatorial search task where extended search can be useful. Rather than making the model more purely execution-heavy, RL appears to redistribute these longer traces away from raw implementation and toward more explicit planning and checking.
Trace length changes are also task-dependent. For Qwen, RL shortens Advanced Geometry traces but lengthens Countdown traces. The Advanced Geometry shortening appears to be driven by the vanilla model producing excessively long traces that frequently hit the maximum token limit and received zero reward. RL fixes this by learning more concise reasoning. The Countdown lengthening shows the model learning to scale inference-time compute on a combinatorial search task where trying more combinations is useful.
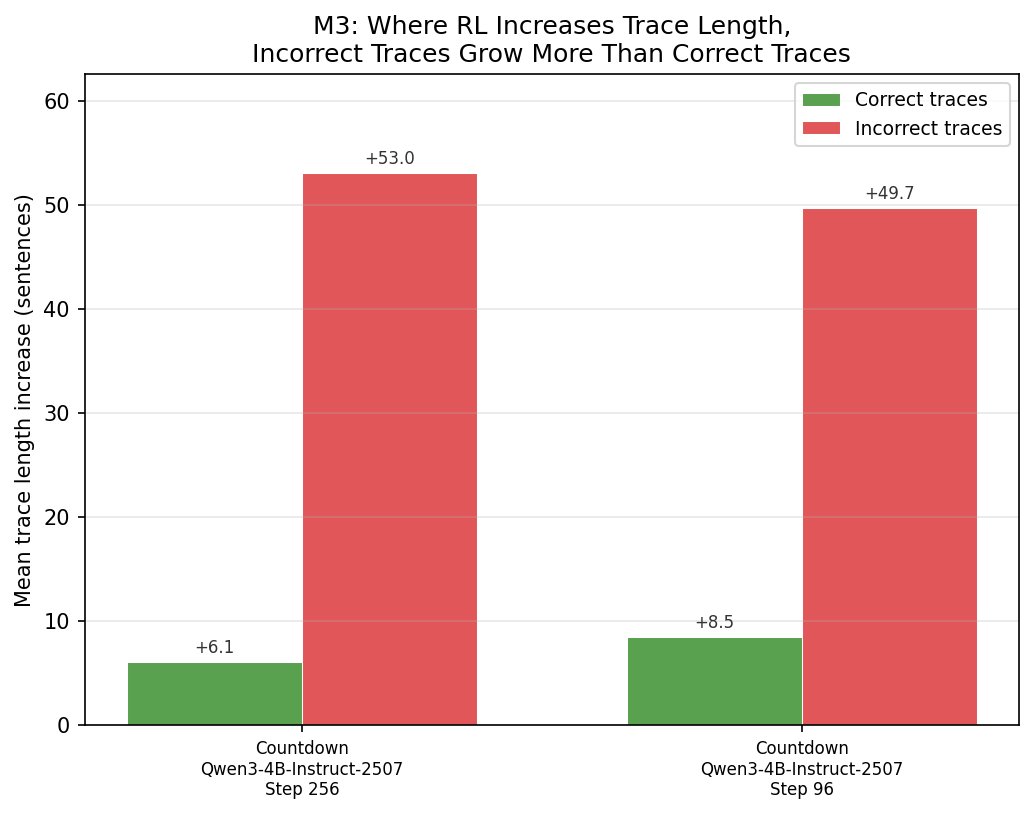
Incorrect traces grow disproportionately. Where RL increases trace length (Countdown), incorrect traces grow substantially more than correct ones. At step 256, correct Qwen Countdown traces increased by a mean of +6.1 sentences relative to vanilla, while incorrect traces increased by +53.0 sentences.
RL Selects for Cognitively Simpler Strategies
Beyond distributional shifts in episode labels, direct inspection of model outputs reveals that RL can reshape which strategies the model employs, favoring cognitively simpler approaches that avoid common sources of error.
Formula Selection on Geometry
The Advanced Geometry task includes incircle-radius problems that require computing triangle area as an intermediate step. We observed two main approaches:
- Heron's formula: \(A = \sqrt{s(s-a)(s-b)(s-c)}\), where \(s\) is the semiperimeter and \(a, b, c\) are side lengths. This requires computing three side lengths via the distance formula (each involving a square root), then a semiperimeter, then another square root. Multiple irrational intermediate values create opportunities for rounding errors.
- Coordinate area formula (Shoelace): \(A = \frac{1}{2}|x_1(y_2 - y_3) + x_2(y_3 - y_1) + x_3(y_1 - y_2)|\). This operates entirely on the given integer coordinates, involves only addition, subtraction, and multiplication, and produces an exact result with no irrational intermediates.
Among the 68 incircle-radius problems in our test set, vanilla Llama uses Heron's formula 85.3% of the time. After 256 steps of GRPO, Heron's usage drops to 0, replaced entirely by the coordinate area formula. A representative example:
Vanilla: "Step 3: Find the area of the triangle using Heron's formula… Area \(= \sqrt{18.835 \times 1.145 \times 9.625 \times 8.065} \approx \sqrt{1334.359} \approx 36.527\)"
Trained (step 256): "Step 1: Find the area… Area \(= \frac{1}{2}|6(-2) + (-7)(-10) + 2(12)| = \frac{1}{2}|-12 + 70 + 24| = \frac{1}{2}|82| = 41\)"
The trained model's approach avoids irrational numbers entirely, reducing the chance of rounding errors that were a frequent source of incorrect answers in vanilla Llama's Advanced Geometry traces.
| Heron's | Coordinate/Shoelace | Other/None | |
|---|---|---|---|
| Vanilla | 58 (85.3%) | 7 (10.3%) | 3 (4.4%) |
| Trained (step 96) | 0 (0%) | 68 (100%) | 0 (0%) |
| Trained (step 256) | 0 (0%) | 68 (100%) | 0 (0%) |
For Qwen on the same task, the coordinate formula was already common before RL. In the step-256 comparison, only 7/200 traces mention Heron's formula at all, and RL eliminates that remaining usage. This suggests the strategy-selection pressure from RL is consistent across model families, though the starting point differs.
Operator Shortcutting on Countdown
A parallel phenomenon appears in Llama's zero-shot Countdown traces. Countdown with 3–4 target numbers can sometimes be solved with addition and subtraction alone, without requiring multiplication or division. The table below shows that RL dramatically reduces the use of multiplication and division.
| Acc. | Uses × | Uses ÷ | Uses + | Uses − | |
|---|---|---|---|---|---|
| Vanilla | 8.0% | 66.0% | 40.5% | 80.5% | 45.0% |
| Trained (step 32) | 25.5% | 2.0% | 0.0% | 99.5% | 31.5% |
| Trained (step 256) | 42.0% | 2.0% | 0.0% | 100.0% | 61.0% |
All correct answers from the trained model at step 256 use only addition and subtraction. This might represent a form of heuristic shortcutting: addition and subtraction might be "cognitively simpler" for the model and less error-prone. One interpretation is that the model is not learning to solve the full space of Countdown problems (which may require multiplication); rather, it is learning to reliably solve the subset that can be handled with simpler operations, achieving higher reward.
This looks perhaps like local-optima behavior: the reward signal from easily-solvable-via-addition problems is sufficient to discourage the model from learning the harder-to-execute multiplication strategies that would be needed for the remaining problems. We note that all 5 problems where vanilla was correct but trained was incorrect required multiplication, consistent with this interpretation.
Slope Formula Correction
We also see a simple positive example of strategy refinement: vanilla Llama occasionally writes the slope formula incorrectly as \((x_2 - x_1)/(y_2 - y_1)\) instead of \((y_2 - y_1)/(x_2 - x_1)\). After RL training, the trained model doesn't make this mistake.
The Prompt Dramatically Shapes RL's Trajectory
Runs 1 and 3 train the same model (Llama) on the same task (Countdown) and differ only in whether a single worked example is included in the prompt.
Zero-shot Llama barely reasons. In the zero-shot condition, vanilla Llama produces traces with a mean length of only 1.2–1.7 sentences, despite having the phrase "Think step-by-step" in the system prompt. RL training does not change this. But accuracy still improves from 8% to 42%, driven primarily by the operator-shortcutting mechanism described earlier.
One-shot Llama develops chain-of-thought. Adding a single worked example to the prompt increases vanilla trace length to ~13 sentences and provides a template for reasoning. RL then amplifies this: trace length increases to ~22 sentences at step 64 before settling to ~15.5 at step 256. The mean-trace behavioral fingerprint shifts dramatically, with Implement rising from 44.1% to 73.7% and the combined share of Plan, Monitor, and Explore dropping from 32.2% to 1.4%. This differs substantially from Qwen's Countdown fingerprint, though some of that structure may itself be seeded by the worked example.
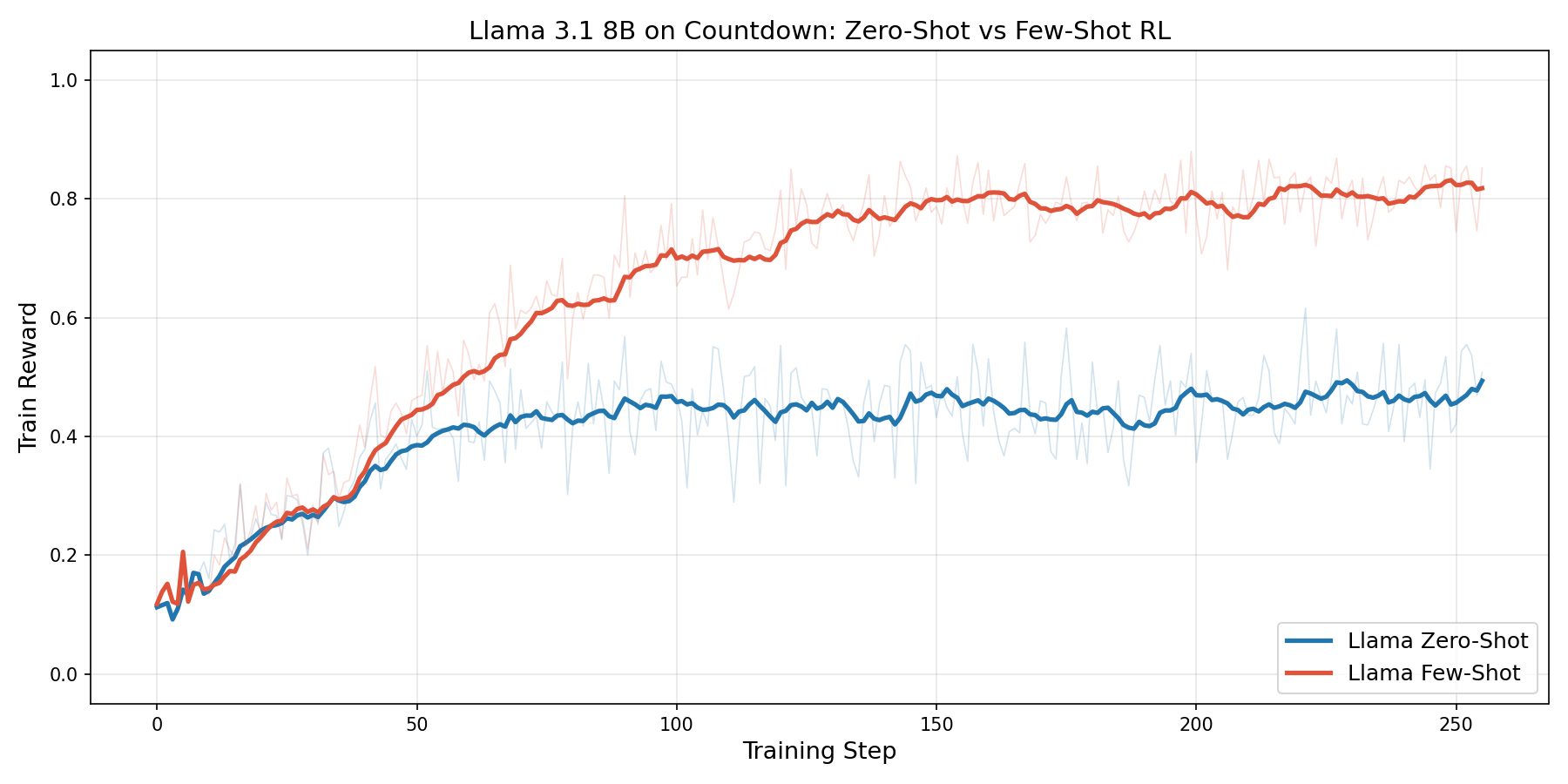
Reward implications. The one-shot condition reaches a final training reward of ~0.82, compared to ~0.49 for zero-shot. The trained one-shot model's traces resemble an elaborated version of the in-context example's structure: it also explores multiple candidate expressions and checks them. The model takes direction from the template but develops it further, scaling the number of candidate checks beyond what the single example demonstrates.
Model Families Differ at Baseline and Under RL
Comparing Runs 4 and 5 (Llama vs. Qwen on Advanced Geometry), we observe that the baseline fingerprints differ. Qwen's vanilla Advanced Geometry traces are longer, with a more distributed fingerprint. Llama's vanilla traces are shorter and more execution-heavy. These baseline differences are consistent with Gandhi et al. (2025)'s finding that Qwen exhibits metacognitive behaviors that Llama does not. We also find that RL modifies the distributions differently. Model choice is therefore a significant moderating variable.
Conclusion
We proposed using before-and-after reasoning-trace analysis to understand what RLVR teaches LLMs. Applying this methodology with Schoenfeld's episode framework across five experimental configurations, we found that behavioral shifts under RLVR are task-dependent, model-dependent, and prompt-dependent. These findings suggest that reasoning-trace analysis can provide a useful and relatively accessible lens for understanding and diagnosing the effects of RLVR. An immediate next step is to add targeted ablations, such as removing the one-shot example at evaluation time, to distinguish prompt imitation from genuinely learned behavior.
References
Agrawal, L. A. et al. (2026). GEPA: Reflective prompt evolution can outperform reinforcement learning. In International Conference on Learning Representations (ICLR). iclr.cc/virtual/2026/poster/10009493.
Gandhi, K. et al. (2025). Cognitive behaviors that enable self-improving reasoners, or, four habits of highly effective STaRs. CoRR, abs/2503.01307. arxiv.org/abs/2503.01307.
Li, M. et al. (2025). Understanding the thinking process of reasoning models: A perspective from Schoenfeld's episode theory. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 18267–18288. aclanthology.org/2025.emnlp-main.922.
OpenAI (2024). Learning to reason with LLMs. OpenAI Release, September 12, 2024. openai.com/index/learning-to-reason-with-llms.
Schoenfeld, A. H. (1985). Mathematical Problem Solving. Academic Press.
Shao, Z. et al. (2024). DeepSeekMath: Pushing the limits of mathematical reasoning in open language models. CoRR, abs/2402.03300. arxiv.org/abs/2402.03300.
Snell, C. et al. (2025). Scaling LLM test-time compute optimally can be more effective than scaling parameters for reasoning. In International Conference on Learning Representations (ICLR). proceedings.iclr.cc.
Stojanovski, Z. et al. (2025). Reasoning Gym: Reasoning environments for reinforcement learning with verifiable rewards. In Advances in Neural Information Processing Systems, Datasets and Benchmarks Track. openreview.net/forum?id=GqYSunGmp7.
Yue, Y. et al. (2025). Does reinforcement learning really incentivize reasoning capacity in LLMs beyond the base model? In Advances in Neural Information Processing Systems. neurips.cc/virtual/2025/poster/119944.
Yuan, L. et al. (2026). From f(x) and g(x) to f(g(x)): LLMs learn new skills in RL by composing old ones. In International Conference on Learning Representations (ICLR). iclr.cc/virtual/2026/poster/10007845.